0. 주제
<전자책 텍스트 분석을 통해 분위기에 맞는 배경음악을 제공해주는 백그라운드 앱>
0.1. 사용 기술
- 사용자의 화면을 캡쳐하여 텍스트를 인식하는 ocr 기술
- 텍스트를 다중감성분류하는 nlp 기술
- 음악을 다중감성분류하는 딥러닝 기술
0.2. 기능
- 메인기능: 실시간 ocr 수행을 기반으로 한 텍스트 분위기에 맞는 배경음악 제공
- 부가기능: - on/off, - 음악 장르 취향 설정, -음악의 fade효과, -예민도 등...
0.3. 진행
- 23년 1학기 캡스톤디자인과창업프로젝트 그로스팀
- flask-firebase 수단은 실패로 끝나 다른 수단을 택했다
1. 데이터 관리
1.1 음악 데이터

firebase web 개발, firebase storage sdk를 사용했다

음성 데이터 다중 감성 분류기를 통해 분류하였다.
위 사진은 '슬픔'으로 판단된 감성을 저장한 firebase storage 모습이다.

중립음악의 경우, 분류기의 결과가 '중립'이다.
위 사진은 '중립'으로 판단된 로파이 장르의 음악을 저장한 firebase storage 모습이다.
1.2. 음악 메타(meta)데이터

firebase realtime database를 사용하여 메타데이터를 저장했다.
디렉토리를 통해 top-down 방식으로 음악 위치를 찾을 수 있다.
감성음악/기쁨/001 의 value로 001.mp3의 위치를 반환한다.
https://romeoh.tistory.com/entry/Firebase-Python-Firebase-Realtime-Database
2. 개발 환경 설정
2.1. flask

python으로 개발하기 위해 flask를 사용했다.
2.2. firebase

firebase hosting sdk를 사용해 배포했다.
2.3. postman


postman을 사용하여 params와 body request에 대한 api 작동을 확인했다.
3. api 코드
3.1. setting

flask, firebase 관련 라이브러리를 import 한다.
firebase sdk를 사용하기 위해 initialize 과정을 거친다.
이 값들은 공개해서는 안된다.

코드의 가장 하단에는 위와 같은 모습이다.
app.run을 통해 대기중인 모습이다.
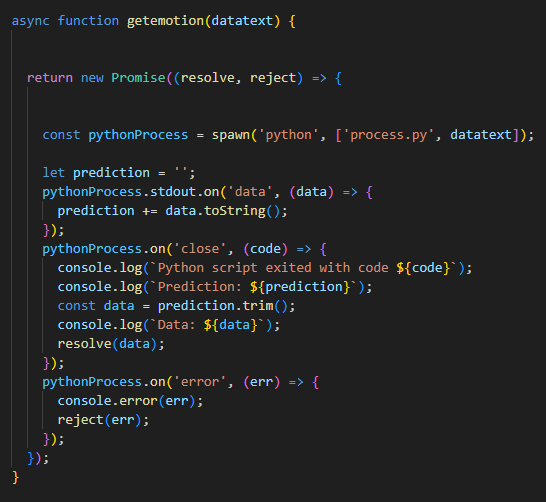
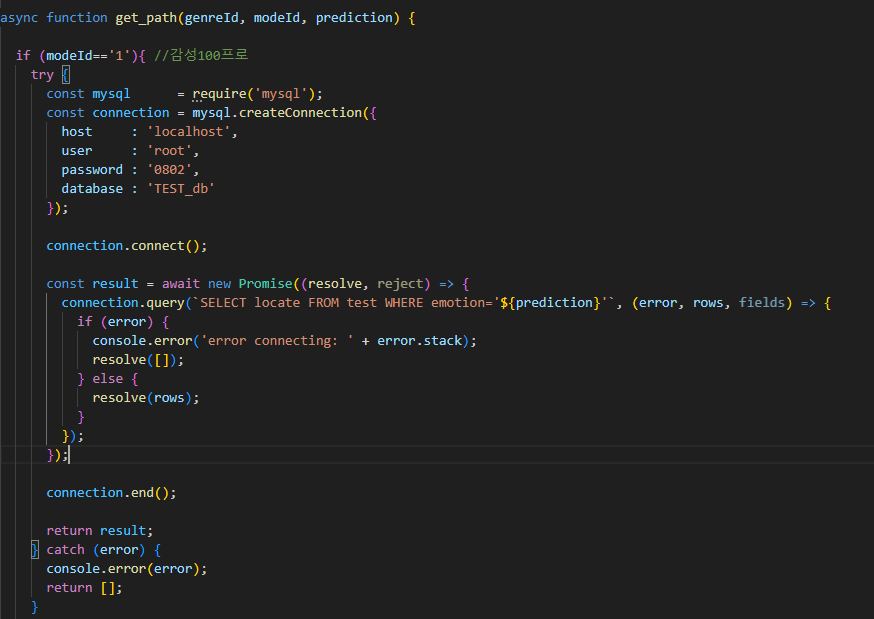
3.2. (nlp)딥러닝 모델과 연동 & 감성분석 결과



genre, mode, prediction을 바탕으로 firebase realtime db에서
우리가 원하는 음악의 메타데이터를 가져오는 함수이다.
mode에 따라 3가지로 구분하였으며,
mode2의 경우, 감성음악과 중립음악이 교차적으로 등장할 수 있도록 구성하였다.
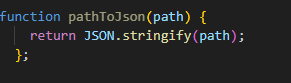
3.3. playlist

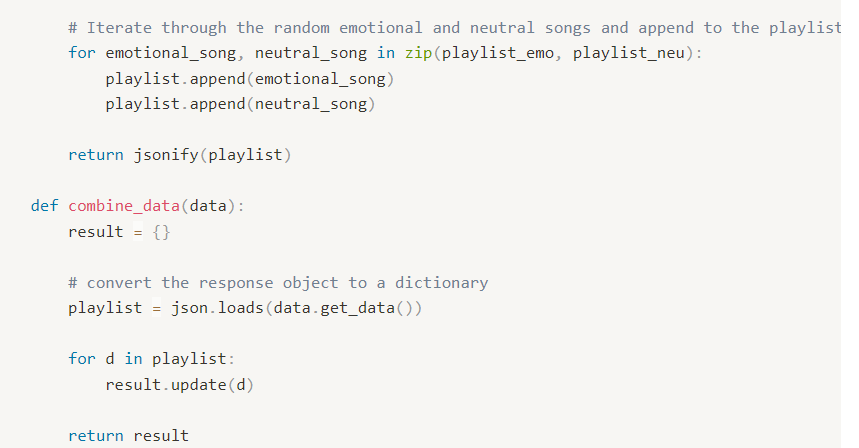
앞 단계에서 얻은 음악 메타데이터를 사용하는 함수이다.
재생할 음악의 위치가 담긴 리스트를 구성함으로써,
재생목록 playlist(json)를 만들 수 있었다.
3.4. streamming

재생할 음악 위치가 담긴 jsonfile을 바탕으로 스트리밍하는 함수이다.
audio/mp3타입으로 반환하며, 현재 곡 종료 후 다음 곡을 자동으로 재생한다.
| request value | 의미 | 사용처 |
| genreId | 음악 장르(=genre) | query를 위한 조건문(if,elif,else) 속 조건 |
| modeId | 재생모드(예민도) | query를 위한 조건문(if,elif,else) 속 조건 |
1. 가장먼저 root url에 의해, genreId, modeId가 생성된 상태에서, 진행된다.
2. nlp 모델결과로 감성prediction을 얻는다.
3. get_genre 함수에서 메타데이터를 얻는다.
4. get_playlist 함수에서 플레이리스트를 얻는다.
5. stream_audio 함수에서 음악을 재생한다.
4. 제언
저자는 firebase, flask를 이용한 api를 개발하려고 했지만, api 배포에 실패하였다.
원인은 firebase hosting에 있었으며, 독자들에게 fibase를 통한 api배포를 추천하지 않는다.
두번째로 시도한 것이 nodejs, aws, filezilla, putty, sql을 이용한 api개발이다.
연동해야 할 기술이 많아 더 복잡하지만, 한번 익히면 그 이후에는 쉬운 방법이다.
api 배포시 방화벽에 막혔는데, 저자는 방화벽을 뚫었지만, 이것이 싫다면, 보안 설정을 잘 하는 것이 좋다.
'대회, 공모전' 카테고리의 다른 글
| [서버] 딥러닝-mysql 연동하는 aws 서버 (0) | 2023.05.12 |
|---|---|
| [딥러닝] 음성 데이터 다중 감성 분류 (audio data multi-emotion classification) (0) | 2022.11.19 |